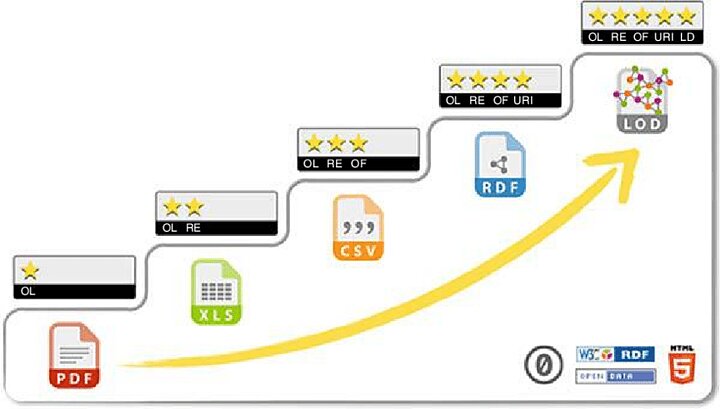
Tak otwarte, jak to możliwe i na tyle zamknięte, na ile to jest konieczne.

Otwarte dane badawcze umożliwiają:
- weryfikację wyników badań – pozwalają na sprawdzenie rzetelności i dokładności przedstawionych wyników;
- ponowne wykorzystanie danych – dane mogą być używane w nowych badaniach, co przyspiesza postęp naukowy;
- wzrost liczby cytowań – publikacje oparte na otwartych danych są częściej cytowane;
- obniżenie kosztów badań – dostęp do istniejących danych redukuje potrzebę ich ponownego zbierania;
- interdyscyplinarność – możliwość wykorzystania danych w wielu dziedzinach.
Otwartość danych badawczych przynosi wiele korzyści:
- przyspiesza rozwój nauki – ułatwia i przyspiesza prowadzenie badań oraz stymuluje dalsze odkrycia i innowacje;
- zwiększa transparentność – umożliwia ocenę wiarygodności prowadzonych badań;
- wspiera współpracę – ułatwia wymianę informacji między naukowcami;
- zwiększa dostępność – dane są dostępne dla wszystkich zainteresowanych.
Otwartość danych sprzyja zwiększeniu rzetelności prowadzenia badań, ponieważ umożliwia niezależną weryfikację wyników. Ułatwia również wielokrotne wykorzystanie danych, także poza pierwotnym kontekstem – co oznacza, że nawet dane pozornie nieistotne mogą okazać się cenne w innym projekcie, innej dyscyplinie czy kraju. Wspiera to rozwój nauki w duchu współpracy, nie rywalizacji.